Filecoin — Deep into SDR algorithm
The algorithm processed by Lotus Sector has switched from window SDR to SDR. The so-called SDR is Stacked DRG (Depth Robust Graph, deep robust graph). The point is that the algorithm removes the “window”. After switching the algorithm, on the Intel CPU, the sector processing (Precommit phase 1) phase took a very long time, exceeding 30 hours. Filecoin official, recommends AMD’s RX 3970x, Sector processing time is about 4 hours. This article delves into the logic of SDR and analyzes the reasons why the Sector is slow to process. The relevant logic is implemented in the rust-fil-proof project. The final submission information of the source code used in this article is as follows:
commit 14870d715f1f6019aba3f72772659e38184378bf
Author: Rod Vagg <rod@vagg.org>
Date: Fri Mar 20 22:30:18 2020 +1100feat(filecoin-proofs): expose filecoin_proofs::pad_reader
Review window SDR algorithm

The window in the window SDR algorithm is the data of each sector, which is first divided into 128M windows. A 32G Sector will be divided into 256 windows. Window and window are independent of each other. Each window performs SDR calculation (labeling encode) separately. A total of 4 layers are required. In other words, between independent windows, do 4-layer operations. The SDR relationship is satisfied between layers.
SDR algorithm
Relative to window SDR, SDR’s algorithm is simpler and rude. A Sector, no longer divides the window. The entire Sector performs SDR calculation and calculates 11 layers. The relevant source code starts from the generate_labels function of storage-proofs / src / porep / stacked / vanilla / proof.rs.
The process of calculating SDR can be split into three steps.
Before calculating the SDR, the entire Sector, every 32 bytes, is divided into nodes. Why split into nodes because of DRG. With nodes, you can determine the relationship between nodes and nodes according to the graph.

Sector data processing is divided into 11 layers. From top to bottom, the upper layer becomes the expansion of the next layer. The dependency relationship between a node on a certain layer and other nodes is as follows:

A node depends on itself and some expanded nodes, among which 6 nodes depend on itself and 8 nodes depend on expansion.
Step 1: Determine base dependencies
To calculate the information of a node in a layer, we must first calculate which nodes this node depends on at this layer. The core logic is the parents function of the BucketGraph structure corresponding to storage-proofs / src / drgraph.rs:
let mut rng = ChaChaRng::from_seed(seed);
for (k, parent) in parents.iter_mut().take(m_prime).enumerate() {
let logi = ((node * m_prime) as f32).log2().floor() as usize;
let j = rng.gen::<usize>() % logi;
let jj = cmp::min(node * m_prime + k, 1 << (j + 1));
let back_dist = rng.gen_range(cmp::max(jj >> 1, 2), jj + 1);
let out = (node * m_prime + k — back_dist) / m_prime;if out == node {
*parent = (node — 1) as u32;
} else {
*parent = out as u32;
}
}
parents[m_prime] = (node — 1) as u32;
simply put:
1) The dependency relationship uses ChaCha20 random generation algorithm.
2) The generated dependencies are all nodes before the current node.
3) The dependent nodes can be repeated.
Step 2: Determine the expansion dependency
After the self-dependency relationship is determined, the extended dependency relationship must be determined, that is, the dependency relationship between the node and the node at the upper layer. The calculation of the first layer is special, and there is no expansion relationship. The core logic is the generate_expanded_parents function of the StackedGraph structure in storage-proofs / src / porep / stacked / vanilla / graph.rs:
let a = (node * self.expansion_degree) as feistel::Index + i as feistel::Index;
let transformed = feistel::permute(
self.size() as feistel::Index * self.expansion_degree as feistel::Index,
a,
&FEISTEL_KEYS,
self.feistel_precomputed, ); transformed as u32 / self.expansion_degree as u32
simply put:
1) The dependency relationship uses the Feistel encryption algorithm (acting as a random number generation), and the specific implementation is in the storage-proofs / src / crypto / feistel.rs file. Feistel algorithm depends on blake2b algorithm.
2) The dependency may be all nodes.
The calculation logic of Feistel is in the file storage-proofs / src / crypto / feistel.rs. After the operation of the 3-layer Feistel structure, the calculation result can be regarded as pseudo-random.
Step 3: Calculate new node information
After determining its base dependencies and extended dependencies, the organization generates the information needed for the new node:
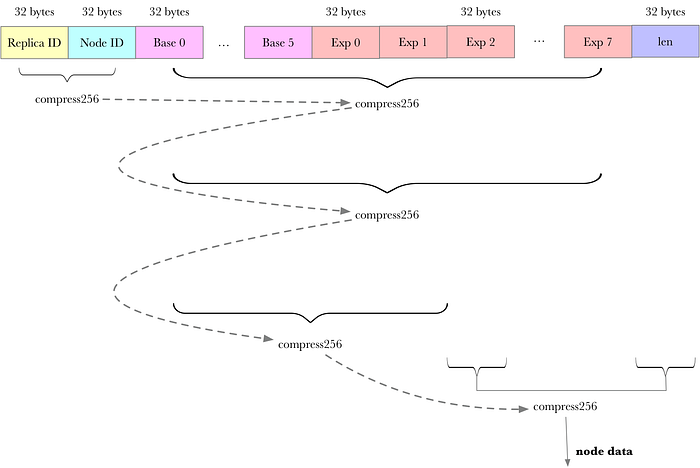
The specific logic can check the copy_parents_data_inner_exp function of the StackedGraph structure of storage-proofs / src / porep / stacked / vanilla / graph.rs.
There are four types of data for compress256 calculation:
1 / ID information, including replica ID and node number
2 / Node data that it depends on
3 / Extend dependent node data
4 / Length information
The results of compress256 of these four types of data depend on each other, and the final output result is the data of the new node.
The calculation of compress256 uses the sha256 algorithm, and the specific implementation is in the file sha2raw / src / sha256.rs.
Why is SDR so slow?
Careful observation of the data of a node on each layer must rely on the first 6 nodes of itself. In other words, to calculate the data of this node, you must first calculate the 6 nodes that depend on it. And this self-dependence is “uniform”. Two meanings, one is that each node depends on 6 nodes, and the other is that if each node operates independently, all the previous nodes need to be calculated again. In short, in the calculation of one layer, it must be calculated one by one in order.
In addition to its own dependencies, there are extended dependencies. Before the calculation of the next layer, the calculation of the previous layer must be calculated. In this case, all 11 layers of calculation are calculated in order, layer by layer, one by one.
The specific calculation is the sha256 algorithm. On Intel’s CPU, the entire 11-layer calculation takes more than 30 hours. On AMD’s TR 3970x CPU, the entire 11-layer calculation takes about 4 hours. An important reason why TR3970x is fast is to support the sha256 ni instruction set.
To sum up:
The calculation of SDR depends on 6 own nodes and 8 expansion nodes. All 11 layers of calculation, layer by layer, are calculated sequentially. The Lotus source code has been optimized for the current SDR implementation, the dependency cache, the pre-reading of node-dependent data and the acceleration of sha256.
