Zero Knowledge Proof — Deep into zkEVM source code (MPT Circuit)
The last two articles introduces the zkEVM circuit and State circuit of the zkEVM:
Let’s anaysis another big section of the zkEVM: MPT Circuit. This article mainly analysis and summarizes zkevm mpt spec and its implementation:
https://github.com/appliedzkp/zkevm-specs/blob/mpt/specs/mpt-proof.md
This article is consist of two parts: 1/ The background information of MPT 2/ Analysis MPT circuit code and theories
1. Background Knowledge
1.1 ETH Account Model
A block in ETH actually has 3 MPTs — state Trie, tx Trie, and receipt Trie.

(https://arxiv.org/pdf/2108.05513.pdf)
From the diagram above, these three roots data are stored on-chain. We mainly focus on the state Trie.
ETH Account is defined as:
Account {
Nonce,
Balance,
CodeHash,
StorageRoot,
}In the mean time, there are 2 types of ETH Accounts:
- EOA(External-Owned-Account): It is the personal account. Corresponding to the data structure above, EOA contains Nonce, Balance, but its CodeHash, StorageRoot are null.
- Contract Account: This account stores the contract informations. Note that the contract code is stored in a property as bytecode of the stateObject (this location is the EVM code ROM in most articles), not in the MPTs. And the bytecode hash is stored in the CodeHash property of the Account. So for a Contract Account, its Nonce and Balance are null, its CodeHash and StorageRoot fields are used.
1.2 RLP Encoding
There’s more specific explations about RLP encoding on wiki.
https://eth.wiki/fundamentals/rlp
1.2.1 RLP Encoding Goal
RLP encodes the following contents:
- A string (ie. byte array) is an item
- A list of items is an item
1.2.2 RLP Encoding Rules
- For a single byte whose value is in the [0x00, 0x7f] range, that byte is its own RLP encoding.
- Otherwise, if a string is 0–55 bytes long, the RLP encoding consists of a single byte with value 0x80 plus the length of the string followed by the string. The range of the first byte is thus [0x80, 0xb7].
- If a string is more than 55 bytes long, the RLP encoding consists of a single byte with value 0xb7 plus the length in bytes of the length of the string in binary form, followed by the length of the string, followed by the string. For example, a length-1024 string would be encoded as \xb9\x04\x00 followed by the string. The range of the first byte is thus [0xb8, 0xbf].
- If the total payload of a list (i.e. the combined length of all its items being RLP encoded) is 0–55 bytes long, the RLP encoding consists of a single byte with value 0xc0 plus the length of the list followed by the concatenation of the RLP encodings of the items. The range of the first byte is thus [0xc0, 0xf7].
- If the total payload of a list is more than 55 bytes long, the RLP encoding consists of a single byte with value 0xf7 plus the length in bytes of the length of the payload in binary form, followed by the length of the payload, followed by the concatenation of the RLP encodings of the items. The range of the first byte is thus [0xf8, 0xff].
All in all,
- The first three rules apply to single string encoding, and the last two apply to list
- Encoding is besicly consist of prefix + content
- prefix = fixed_prefix + content_length
- fixed_prefix varies based on its content length
1.2.3 RLP Example
The string “dog” = [ 0x83, ‘d’, ‘o’, ‘g’ ]
The list [ “cat”, “dog” ] = [ 0xc8, 0x83, 'c', 'a', 't', 0x83, 'd', 'o', 'g' ]
The empty string (‘null’) = [ 0x80 ]
The empty list = [ 0xc0 ]
The integer 0 = [ 0x80 ]
The encoded integer 0 (’\x00’) = [ 0x00 ]
The encoded integer 15 (’\x0f’) = [ 0x0f ]
The encoded integer 1024 (’\x04\x00’) = [ 0x82, 0x04, 0x00 ]
The set theoretical representation of three, [ [], [[]], [ [], [[]] ] ] = [ 0xc7, 0xc0, 0xc1, 0xc0, 0xc3, 0xc0, 0xc1, 0xc0 ]1.3 Compact Encoding
Compact encoding and MPT informations also uses the wiki reference.
https://eth.wiki/fundamentals/patricia-tree
1.3.1. Compact Encoding Content
- A hex sequence is split into nibbles, which are 4 bits of a hexadecimal number (i.e., it has values of 0 — f).
- The hex sequence may or may not have an Optional terminator. The terminator is 0x10.
1.3.2 Compact Encoding Rules and Example
> [ 1, 2, 3, 4, 5, ...]
'11 23 45'- If there is no terminator and the encoding length is odd
- So add 1 to the head and each two nibbles are grouped together
> [ 0, 1, 2, 3, 4, 5, ...]
'00 01 23 45'- If there is no terminator and the encoding length is even
- So add 00 to the head and each two nibbles are grouped together
> [ 0, f, 1, c, b, 8, 10]
'20 0f 1c b8'- If there is a terminator and the encoding length is even excluding the terminator(the terminator doesn’t count in the encoding)
- So add 20 to the head and each two nibbles are grouped together
> [ f, 1, c, b, 8, 10]
'3f 1c b8'- If there is a terminator and the encoding length is odd excluding the terminator(the terminator doesn’t count in the encoding)
- So add 3 to the head and each two nibbles are grouped together
Summary:
- Based on whether there is a terminator or not, there’re two different sets of prefix. Use (0, 1) if there’s no terminator, and use (2, 3) if there is a terminator.
- Adding prefix makes the total length even when including the prefix(to enable coding to be done in pairs), so sometimes, 0 need to be added to adjust.
1.3.3 The Application of Compact Encoding in MPT
- Leaf node has terminator and extension node doesn’t.
- The path of the node is encoded.
Which are all shown in the following table [1].
hex char bits | node type partial path length
----------------------------------------------------------
0 0000 | extension even
1 0001 | extension odd
2 0010 | terminating (leaf) even
3 0011 | terminating (leaf) odd1.4. Merkle Patricia Trie (MPT)
ETH is used to store states as a dictionary tree, which stores (key, value), and the key represents the path of the tree.
1.4.1 Patricia Trie
As shown above, here are the key points to know:
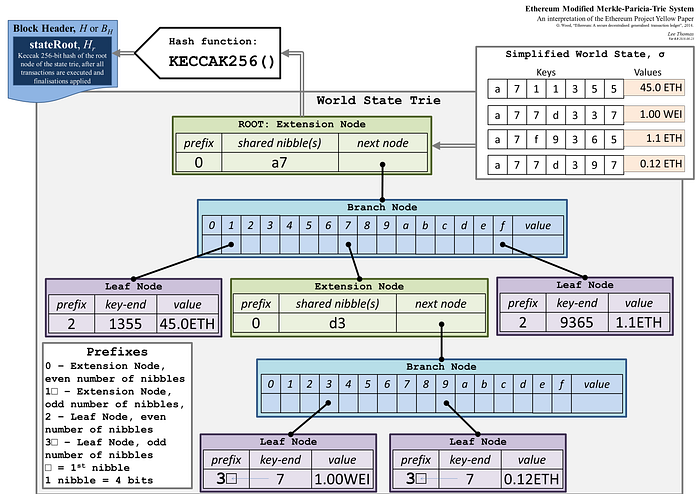
- 4 types of node
- NULL (represented as the empty string)
- Branch Node: A 17-item node [ v0 … v15, vt ]
- Leaf Node: A 2-item node [ encodedPath, value ]
- Extension Node: A 2-item node [ encodedPath, key ]
2. The hash value of the child node is stored in the nibble of the branch node and the next node of the extension node. (When one node is referenced inside another node, what is included is H(rlp.encode(x)), where H(x) = sha3(x) if len(x) >= 32 else x and rlp.encode is the RLP encoding function).
1.4.2 State Trie & Storage Trie
The State Tire informations are:
- key = sha3(eth_address)
- value = rlp(eth_account)
The Storage Tire informations are:
- key = sha3(contract_var_position)
- value = rlp(contract_var_value)
2. MPT Prooof
This section is an introduction and overview of the ZKEVM MPT SPEC.
2.1. What does MPT need to Prove?
The purpose of MPT circuit is:
MPT circuit checks that the modification of the trie state happened correctly.
To do this, the principle is to handle one change in the state root caused by one value change at a time. This is the implication of the original statement as follows:
The circuit checks the transition from val1 to val2 at key1 that led to the change of trie root from root1 to root2 (the chaining of such proofs is yet to be added)
The problem further reduces to proving the correctness of two paths: path1: (key1, val1) -> root1, path2: (key1, val2) -> root2, and by proving the correctness of a path, we prove that the hash of all child nodes on the path appears at the correct position of the parent node.
Based on this, several aspects need to be addressed as follows:
- How to completely represent the information of a path
- How to represent former state and latter state
- How to represent Branch, Extension, Leaf in MPT
- How to verify the accuracy of the Hash
- How to prove that the Hash appears in the proper location
- How to prove the correctness of the key (i.e. address/position)
2.2. Representations of the complete path, former state and latter state
2.2.1. Complete Representation of the path
From the figure above, the layout of the circuit is identical to the real path. There are three sections included as below:
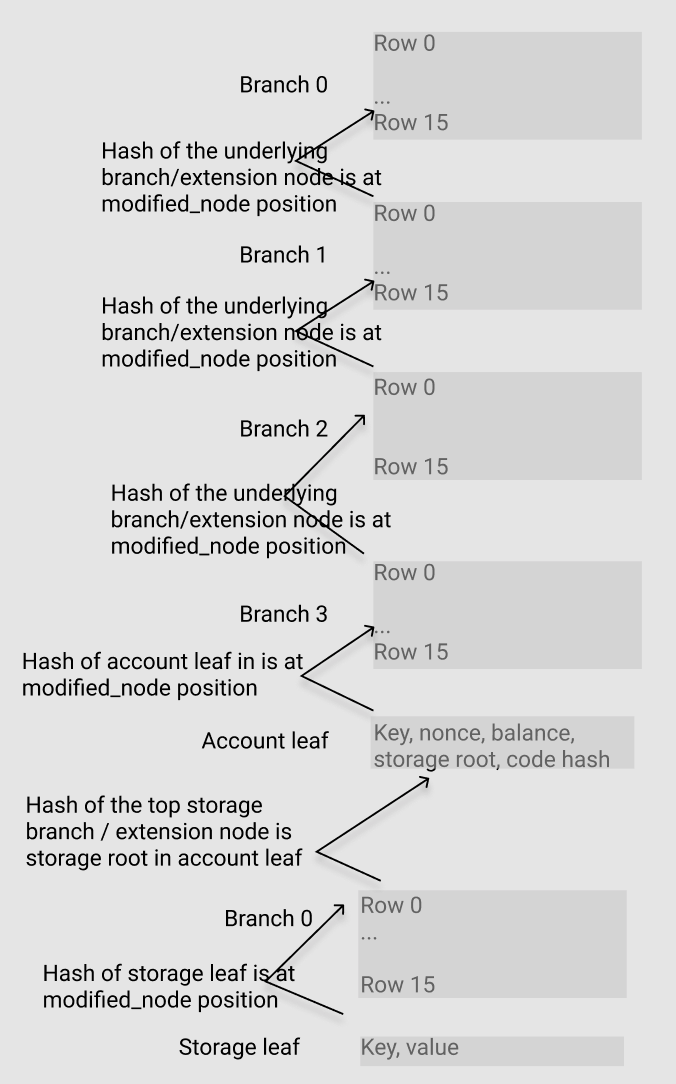
- storage leaf
- branch node (including extension node)
- account leaf
Something to note: The dash arrows in the figure represent the correct position of the child node Hash in the parent node. These are represented in the constraints that need to be proved, which is frequently used in the spec.
2.2.2. Representation of former state and latter state
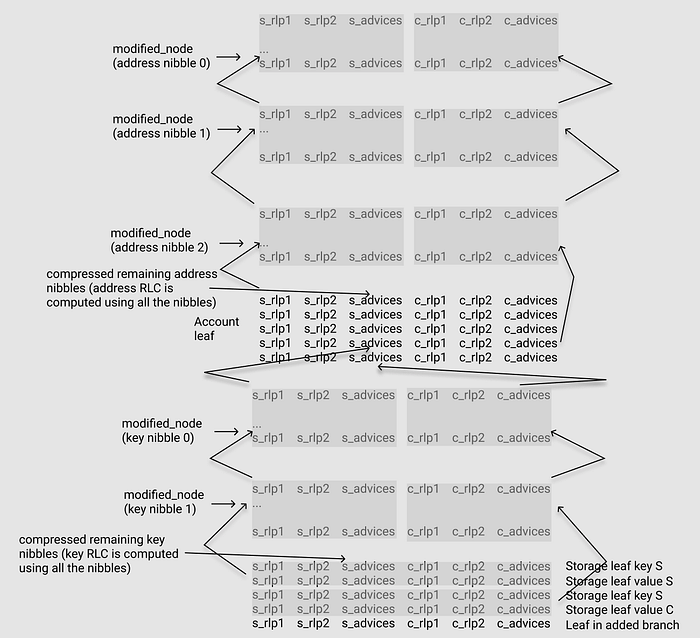
From the figure above:
- Two path proofs — S and C — are put side to side. With S representing former state and C representing latter state.
2.2.3. MPT Proof Overview

The picture above explain the function of MPT Circuit in detail, which can prove the two MPT Paths.
2.3. The representation and relationship of Branch/Extension Node
2.3.1. Representation of Branch Node
Branch/Extension Node can be viewed as one block in the circuit, as shown clearly in the figure below:
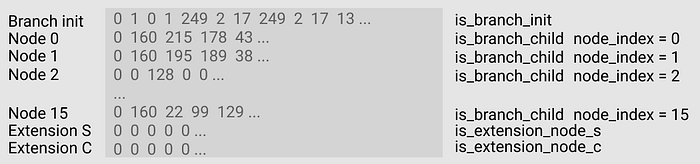
it’s the same function block in a circuit
There are 19 lines in this function block, they are:
- the first row — branch init
- The next 16 rows — each representing a nibble (0 ~ f).
- The last two rows — the information of two extension nodes.
There are 34 columns in this function block, they are:
- The first column represents the remaining rlp length after excluding the rlp encoding of this row
- The second column represents the prefix of the rlp encoding.
- The next 32 columns represent the 32 bytes of the Hash, with each column storing one byte.
- The branch init row stores information about the branch node, such as the RLP encoding information, and the associated selectors.
2.3.2. Representation of Extension Node

Although it is the same function block, the extension node is actually represented in the last two rows. Also, these two rows span across the S and C blocks. These two rows are:
- The S block of the S row (s_rlp1, s_rlp2, s_advices) represents the key of the extension node (the key itself is compact encoded, while its storage is sequenced with rlp encoding).
- The C block of the S row represents the rlp encoding of the value (i.e., the hash of the child node) of the extension node S (i.e., the former ext node).
- The S block of the C row represents a part of the extension node key, which serves to make decoding easier. The reason for not storing the full key here is that the former ext node (S) has the same key as the latter ext node ( C ).
- The C block of the C row represents the rlp encoding of the value (i.e., the hash of the child node) of extension node C (i.e., the latter ext node).
2.3.3. Relationship between Branch/Extension Node
- For branch node, if the block above represents the branch node, then its last two rows (extension S/C) are null
- For an extension node, it is only necessary to understand the rows for branch nodes. In short, these lines are not null, but represent the child branch nodes, as shown in the following diagram.

In other words, the hash of the extension node is in the previous block, and the hash of the branch node in this block is stored in the extension node.
2.4. Representation of Leaf
There are two types of leaf nodes, Account leaf and Storage leaf, both of which are represented by 5 rows with different meanings.
2.4.1 The representation of Account Leaf
Key S
Nonce balance S
Nonce balance C
Storage codehash S
Storage codehash C
Two things to note here:
- The same account of former state and latter state has the same address, so the key is represented by only one row.
- These five rows also span across the two sections of S and C.
2.4.2. The representation of storage Leaf
Leaf key S
Leaf value S
Leaf key C
Leaf value C
Leaf in added branch
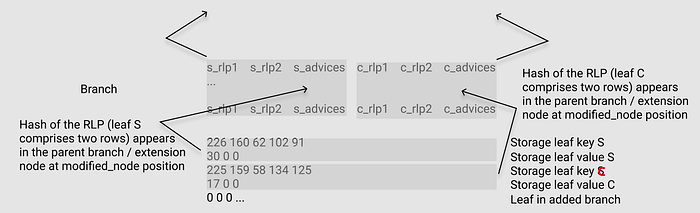
Two points to note:
- The key S and C might be different, e.g. in the case of inserting or deleting a node.
- Each row spans across the two sections of S and C.
2.5. How to prove the accurcy of Hash and its location
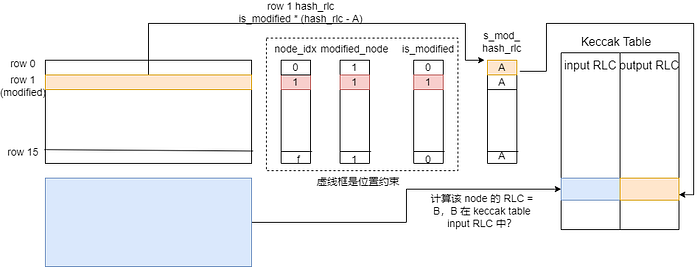
- These 3 columns of mode_index, modified_node, and is_modified are designed to constrain the location
- is_modified and s/c_mod_hash_rlc are designed to constrain the hash_rlc on the path. As shown in the figure, s/c_mod_hash_rlc of the node has the same value, which is convenient to define constraints. In the figure above, the hash_rlc of row 1 is equal to the hash_rlc of A.
- The keccak table ensures the correctness of hash calculation.
- The rlc of the child node should be in the input column of keccak table.
- A should be in the output column of keccak table.
With the constraints above, it’s able to prove that the hash of the child node is correct and at the right location of the parent node.
2.6. Hash based RLC Computation
This section talks about the hash based rlc computation, including rlc computation of branch node, extension node, account leaf, and storage leaf, which is deeply explained in spec. Let’s foucs on the key points and challenging parts.
2.6.1. Branch node RLC
Branch node RLC is consist of two parts, the 1st one is the rlc of branch rlp encoding information stored in branch init row, and the 2nd part is the rlc of branch node rows.
The 1st part is shown as follows:
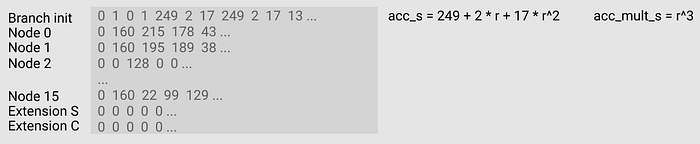
Just note the position of the rlp code in the branch init row:
- Columns 4, 5, 6 are the rlp meta of the branch node S (which is s_advices[2–4] in the source code), and columns 7, 8, 9 are the rlp meta of the branch node C (which is s_advices[5–7] in the source code). The reason to use 3 columns is the length of the unencoded data of the node. If long, as shown in the example, it takes three bytes; if short, for example, it takes two bytes for the node having lots nulls.
- The mark of length (two bytes or three bytes) is the first four positions in the branch init row. Columns 0, 1 (s_rlp1, s_rlp2 in the code) are the byte length of S rlp; columns 2, 3 (s_advices[0], s_advices[1] in the code) represent the byte length of C rlp.
- (1, 0) represents two bytes, (0, 1) represents three bytes.
- The acc_s column represents the rlc result, and the acc_mult_s column represents the random number (power of r) at the beginning of the current row.
The the computation of branch node rlc is shown below:

Mark that s/c_rlp1 doesn’t count in the computation of branch node rlc, which means the computation for every row starts from s/c_rlp2.
Finally, when computing branch node rlc, it is important to check whether the length stored in the init line is correct or not, shown in Figure below:

Note that:
- As mentioned above, the total length is stored in the init row
- The rlp1 of row 0 — row 15 in the branch node stored the remaining length excluding the length of the row. So the constraint is s/c_rlp1_pre = s/c_rlp1_cur + cur_row_len
- At row 15, the remaining length is required to be not equal to 0 (currently it is required to be equal to 1), because there might be a value that comes after it.
2.6.2. Extension node/Account leaf RLC
This part is simple. It is just to calculate the values of the corresponding rows in turn and get rlc, so it is not even explained in the spec, although implemented in the source code.
2.6.3. Storage leaf RLC
Usually when the key don’t change, the calculation is simple and same as extension node/account leaf rlc. But there’re some special cases, where the storage changes by adding or deleting nodes.
case 1: Leaf turns into branch / extension node
Branch 0 | Branch 0
| Branch 1
Leaf 1 | Leaf 2You only need to understand the following points to handle this case:
- This situation is caused by the insertion of Leaf 2, which causes a change in the hierarchy of Leaf 1. Note that it is not the change in Leaf 1 itself that triggered this situation.
- So spec says that now Branch 1 has two leaves: Leaf 1 and Leaf 2. The new Leaf 1 is not shown above, so we use Leaf 11 to represent the Leaf 1 under Branch 1. So Leaf 1 is exactly the same as Leaf 11, except that the key in Leaf 11 is shorter due to the hierarchy change.
- Leaf 11 is stored in the fifth row of the storage leaf, which is the Leaf in addition branch. In spec, Leaf 1 is “drifted” to Leaf 11.
- As Leaf 1 drifts, the hash of Leaf 2 connects to the modified_node of Branch 1, at the same time, the hash of Leaf 11 connects to the drifted_mod of Branch 1.
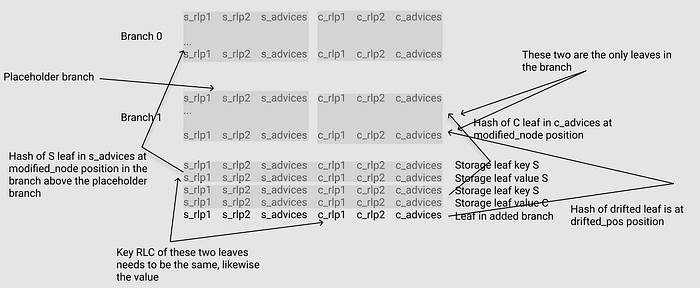
The basic constraints can be found in the figure above:
- Hash of Leaf 1 is in the modification_node of S Branch 0
- Hash of Leaf 2 is in the modification_node of C Branch 1
- Hash of Leaf 11 is in the drifted_mod(pos) of C Branch 1
- The key and val of Leaf 1 and Leaf 11 should be identical
In order to keep the balance of the original branch block, the concept of placeholder branch is introduced, which is S branch 1 in the figure above. Here are the points to master:
- This placeholder looks exactly like the other branch node (the so-called counterpart in the documentation) ; specifically, if S is a placeholder, then it looks exactly like the C branch node alongside it, and vice versa.
- The advantage of this is that it satisfies the general constraint between S branch node and C branch node, i.e., they are the same at non-modified_node. (branch.rs)
- More specifically, all non-drified_pos rows at non-modified_node should be null. (branch.rs)
- From the code, there is no direct constraint on the location of the added branch (Leaf 11) hash at drifted_pos in C branch 1. What is really constrained is that the hash of Leaf 11 is in the placeholder. (leaf_key_in_added_branch.rs)
With this analysis in hand, the case of deleted nodes can be handled accordingly.
case 2: Key not used yet
Branch 1 | Branch 1
| Leaf 2For this case, it also uses the placeholder. However, the placeholder appears on the leaf this time.
Branch 1 | Branch 1
Leaf 1 | Leaf 2Note that spec didn’t mention the handling of the witness of the placeholder leaf. For now, it is required to set to 0 in the code (leaf_value.rs).
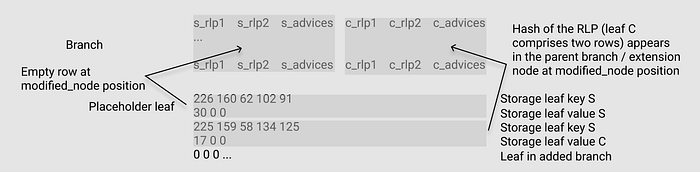
What is unique here is that the hash of the placeholder leaf at the corresponding position of the parent node should be null.
With this understanding, we can understand case 3 and case 4 in spec, which are the cases of case 1 and case 2 occurring at the first level.
2.7. Key RLC Calculations
Key RLC is calculated to prove the correctness of the address and position for a complete path, which has three types: branch node, extension node and leaf, as described below.
In general,
- Address and position are both keys, 32 bytes, and 64 nibbles.
n0n1, n2n3, ..., n62n632. So the rlc of the key is calculated as
key_rlc = (n0 * 16 + n1) + (n2 * 16 + n3) * r + (n4 * 16 + n5) * r^2 + ... + (n62 * 16 + n63) * r^313. The reason for discussing the three cases is that the nibbles that make up the key are scattered among the three nodes, and the ultimate goal of the discussion is to correctly identify the location of the next nibble.
4. The reasons for this complexity are the Compact encoding and the fact that the nibbles are scattered among the three nodes.
2.7.1. Branch node key RLC
The computation of the branch node key rlc is the most straightforward, because each branch node has only one nibble (i.e., a row in the branch node) to participate in the computation in the mpt proof, and all that needs to be distinguished is whether the nibble is C16 or C1, which is determined by the selector in the branch init row.
The process is as follows:

2.7.2. Extension node key RLC
Extension node key rlc calculation is based on the same principle, except that
- the extension node is in the middle of the path (as opposed to the leaf node)
- extension node may store more than one nibble (as opposed to branch node)
- the existence of the compact encoding of the key
- the existence of the rlp encoding of the entire node (in the case of only one nibble)
So, the computation of the extension node key rlc requires the most discussion, which is where spec spends a lot of time on. But it is actually simple, and the following is a direct example of spec.
If the nibble stored in the extension node is an even number, for example:
[228,130,0,149,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]Note that the first two bytes are rlp-encoded and can be ignored. What is really useful is the two bytes 0 and 149, which are represented in hexadecimal as 00, 95. According to the compact encoding rules, this means that the key stored in this extension node has an even length (2 in this case) and the value is 95. It is important to keep in mind that this only represents the case of this row, and what needs to be discussed here is whether 9, 5 in the key should be C16 or C1.
- If the number of nibbles ahead of the extension node is an even number, this means that 95 is a byte of the key and can be directly involved in the computation by finding the correct power of r. The calculation is:
key_rlc = key_rlc_prev + 149 * key_rlc_mult2. If the number of nibbles ahead of the extension node is odd, this means that 9 is actually the low part of the previous byte of the key, and 5 is the high part of the next byte in the key. So the calculation is:
key_rlc = key_rlc_prev + 9 * key_rlc_mult + 5 * 16 * key_rlc_mult * rIf the nibble stored in the extension node is an odd number, for example:
[228,130,19,149,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]The hexadecimal representation of the example 19, 149 is 13, 95, which means that the nibble length of the extension node is odd and the nibbles of the contained keys are 3, 9, 5. The core of the following discussion is still the question of which is C16 and which is C1.
- First, if the number of nibbles on the extension node is even, 3 is the high part, 9 is the low part, and 5 is the high part. The calculation is as follows:
key_rlc = key_rlc_prev + ((19 - 16) * 16 + 9) * key_rlc_mult + 5 * 16 * key_rlc_mult * r- The number of nibbles on the extension node is odd. Then 3 is the low part and 95 is a complete byte. This is calculated as:
key_rlc = key_rlc_prev + (19 -16) * key_rlc_mult + 149 * key_rlc_mult * r2. The last case is when there is only one nibble in the extension node. In this case, the rlp encoding changes again, i.e. there is no more length representing byte (130 in the example above). For example:
226,16,160,172,105,12...In this case, the nibble stored in the extension node is 0. The specific calculation is the same as above, and is related to whether the number of nibbles before the extension node is odd or even. Figure the formula out from the references by yourself.
The discussion above clearly explains the key rlc calculation in the extension node. The selectors mentioned in some specs specifically control the cases above.
2.7.3. Leaf Key RLC Calcualtion
Based on the discussion above, the calculation of the leaf key rlc is easier now. Since the leaf node has no more child nodes, its situation is much simpler. Because if it stores an even number of nibbles, the number of nibbles before the leaf must be odd; if it stores an odd number of nibbles, the number of nibbles before the leaf must be even. The calculation of key rlc in these two cases has been discussed in the extension node key rlc calculation.
The number of nibbles in the leaf is determined by the rlp encoding of the leaf key, mainly whether the length is greater than or less than or equal to 55, which will not be repeated here.
2.7.4. Constraint of the key correctness
It is very simple here, there’s no lookup used. The code only uses a simple equality constraint. (leaf_key.rs)
3. MPT Circuit Resource Consumption
Until now, the whole MPT circuit is rather large. The consumption of resources related to the whole mpt circuit up to now is:
advice column: 108
fixed column: 7
instance column: 1
custom gates: 42
So far, the core modules of zkEVM have been analyzed. zkEVM is a very meaningful zk application and is currently the largest and most complex zk system in terms of circuit size. If you are interested, you are welcomed to do more research with us.
